Auto-Seeding Ethical Torrents
Ever since I've been on the modern internet I've always felt like I could be contributing, digitally that is. I wanted to feel like I was helping to make the internet a better place, I wanted to feel like I was supporting the true spirit of the internet.
I have found a few ways to contributed over the years, this blog is one, Open sourcing code is another and running a Folding@Home client. The one I want to talk about today is Torrents. No, not stolen movies or games but useful, practical data.
I love the decentralised concept of torrents, honestly they feel like
I would always leave the torrents I downloaded seeding to others but I wanted to go further, I wanted to share more than just the data I happened to need. I wanted to be able to automatically seed all the versions of a thing as soon as they became available.
I put this off for a while because I thought it was going to be a bit of a pain, turns out it's really quite easy.
The Setup
I run the Transmission client, I use this client because it was the first one I ever used, and it's never given me a reason to change. It turns out that it is ideally suited to automatically seeding torrents too. It can:
- Watch a directory for torrents to add
- Limit bandwidth on a schedule so it doesn't affect my network during waking hours.
- Support various different Torrent protocols
- Be run headless via Docker
All that I needed to do was download the torrent files as they became available and drop them in the right directory. I choose to keep this dead simple and write a BASH script.
#!/bin/bash set -e indexPageUrls=( "https://ubuntu.com/download/alternative-downloads" "https://www.linuxmint.com/edition.php?id=311" "https://www.linuxmint.com/edition.php?id=313" ) torrentUrls=(); for indexPageUrl in "${indexPageUrls[@]}"; do while IFS= read -r torrentUrl; do torrentUrls+=("${torrentUrl}") done <<< "$(curl "${indexPageUrl}" --compressed --silent -H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:123.0) Gecko/20100101 Firefox/123.0' -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8' -H 'Accept-Language: en-US,en;q=0.5' -H 'Accept-Encoding: gzip, deflate, br' -H 'Alt-Used: www.raspberrypi.com' -H 'Connection: keep-alive' -H 'Upgrade-Insecure-Requests: 1' -H 'Sec-Fetch-Dest: document' -H 'Sec-Fetch-Mode: navigate' -H 'Sec-Fetch-Site: none' -H 'Sec-Fetch-User: ?1' -H 'Pragma: no-cache' -H 'Cache-Control: no-cache' -H 'TE: trailers' | grep -oE '"[^"]+\.torrent"' | grep -oE '[^"]+')" done # Raspberry Pi Images while read -r torrentUrl; do torrentUrls+=("${torrentUrl}") done <<< "$(curl "https://downloads.raspberrypi.com/rss.xml" --silent | grep -Eo '>[^ ]+\.torrent<' | grep -Eo '[^<>]+' | tail -n 35)" # Latest EN Wiki torrentUrls+=("$(curl --compressed --silent "https://meta.wikimedia.org/wiki/Data_dump_torrents" | grep -oE 'href="[^"]+">enwiki-[^-]+-pages-articles-multistream' | grep -oE '"[^"]+"' | grep -Eo '[^"]+' | head -n 1)") # Latest Arch torrentUrls+=("https://archlinux.org$(curl --compressed --silent "https://archlinux.org/releng/releases/" | grep -oE '/releng/releases/[^/]+/torrent/' | head -n 1)") # Latest Debian DVD torrentUrls+=("https://cdimage.debian.org/debian-cd/current/amd64/bt-dvd/$(curl --compressed --silent "https://cdimage.debian.org/debian-cd/current/amd64/bt-dvd/"| grep -oE '"[^"]+\.torrent"' | grep -oE '[^"]+' | head -n 1)") # Latest Tail OS torrentUrls+=("$(curl --silent https://tails.net/install/download/index.en.html | grep -oE '.+\.torrent' | grep -oE '[^"]+' | head -n 1)") # Latest Kali Linux torrentUrls+=("$(curl --silent https://www.kali.org/get-kali/ | grep -oE 'https://.+\.torrent' | grep 'installer-amd64')") # Latest Ubuntu Mate 22.04 torrentUrls+=("https://cdimages.ubuntu.com/ubuntu-mate/releases/22.04/release/$(curl --compressed --silent "https://cdimages.ubuntu.com/ubuntu-mate/releases/22.04/release/"| grep -oE '"[^"]+\.torrent"' | grep -oE '[^"]+' | head -n 1)") # Latest Ubuntu Mate 24.04 torrentUrls+=("https://cdimages.ubuntu.com/ubuntu-mate/releases/24.04/release/$(curl --compressed --silent "https://cdimages.ubuntu.com/ubuntu-mate/releases/24.04/release/"| grep -oE '"[^"]+\.torrent"' | grep -oE '[^"]+' | head -n 1)") # Latest Fedora Workstation X86 torrentUrls+=("$(curl --silent https://torrent.fedoraproject.org/ | grep -oE '"[^"]+\.torrent"' | grep -oE '[^"]+' | grep 'Workstation' | grep 'x86_64' | grep -v 'Beta' | head -n 1)") # Latest Fedora Server X86 torrentUrls+=("$(curl --silent https://torrent.fedoraproject.org/ | grep -oE '"[^"]+\.torrent"' | grep -oE '[^"]+' | grep 'Server' | grep 'x86_64' | grep -v 'Beta' | head -n 1)") for torrentUrl in "${torrentUrls[@]}"; do torrentDirectory="~/torrents/" torrentName="$(curl --silent --head "${torrentUrl}" | grep -Eo 'filename=\S+' | grep -Eo '[^=]+' | grep -Eo '[^"]+' | tail -1)" torrentName="${torrentName:-${torrentUrl##*/}}" echo -n "Found ${torrentName} => " if [[ -f "${torrentDirectory}/${torrentName}" || -f "${torrentDirectory}/${torrentName}.added" ]]; then echo "Already downloaded" continue fi echo "Downloading..." curl \ --silent \ --location \ --remote-name \ --remote-header-name \ --output-dir "${torrentDirectory}" \ "${torrentUrl}" done
It looks gnarly, but it's fairly straight forward
- Fetch the site using curl
- Parse URLs which end with
.torrent - Check if we have already downloaded the torrent
- If not download to the right directory
This script is simply invoked by a daily cron job.
I like how easy it is to extend and add new URLs or do some specific parsing for one site. I had to do this recently when the main RaspberryPi site started using CloudFlare which blocked my requests.
Is It Making A Difference?
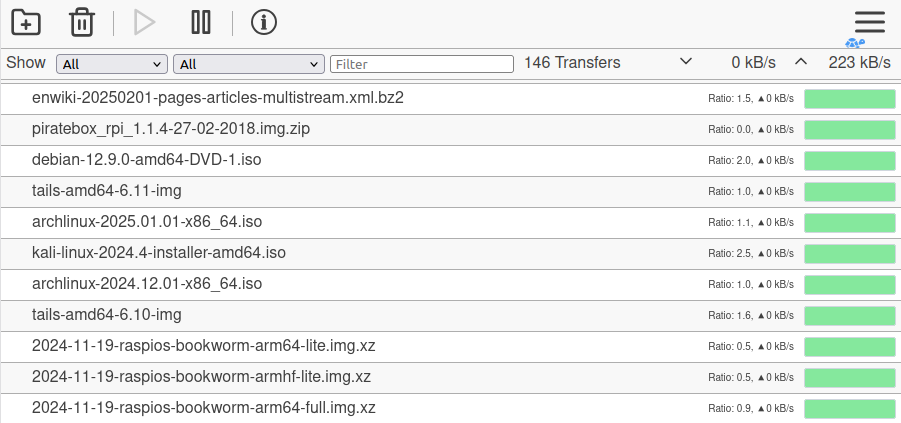
I believe so. My current client has been running for over a year now and during that time seeded 146 torrents. Looking at the bandwidth stats shows that I have uploaded 1.6x as much data as I've downloaded (622 GB vs 375 GB), that certainly seems like a net benefit.
Most of the shared data is Linux distro, but it makes me happy to see Wikipedia is not only on the list, but it alone accounts for 18% of the uploaded bandwidth. Wiki is exactly the kind of thing I want to be a part of sharing and making available to everyone, I'd love to find more similar torrents, like scientific papers or literature.